
I have been tasked, by process of elimination, with developing exe.dev’s marketing strategy.
In one very important sense, marketing exe.dev is easy. I am proud of what we have built, so I am happy to talk about it to anyone who will do me the kindness of listening. Being happy enough with my work to talk about it is rare for me, and usually the biggest hurdle.
In another sense, it is the worst time to talk about anything. The over-the-top marketing around AI is tiring. Yes, the technical possibilities created by LLMs are wondrous. I have not been this excited about computers since I got a modem! Yet the noise is deafening.
With general SNR so low, the only marketing strategy that makes sense to me is: Show, don’t tell.
It turns out we are already doing this, to an extent. We built a landing page back in December that was described by the top comment on HN as “the worst website ever” because all it does is tell you to ssh exe.dev. Even there, what we show you is the infrastructure we built, that your agent needs. You need VMs. Lots of VMs. You need TLS and auth taken care of for you. You need it easy enough to use an agent can figure it out and have context window left over to write your program.
This strategy is going really well! A lot of users have shown up, asking technical questions and we are growing rapidly.
But along the way, it is easy for a lot of the value of the product to be hard to discover. I would like to tell you about one, but in the spirit of “show, don’t tell” let me show you something I have done with it.
Write private apps from your phone. Share them.
So I am going to walk through an example of the most powerful feature that is hard (today) to discover from our home page:
Shelley is for your phone
In our default VM image, we install codex and claude. We also include our own agent, Shelley. It is the second general-purpose programming agent we have written, and we wrote it for a very particular reason: we need an agent with a web UI.
The need for a web UI is debatable on a desktop. There are clear advantages, but also drawbacks. But on mobile the case is clear. I’m not going to press a teeny tiny “Ctrl+Z” button in an iOS terminal emulator. Sorry. I need all the affordances of mobile UI design from the past 19 years to be able to use such a tiny screen without a real keyboard.
With this, you can visit exe.dev/new and type in a prompt. We start a VM, and feed the prompt to the copy of Shelley running on your VM. Because it’s a fresh, isolated VM we have no permission nagging, the agent is root and can do whatever it needs to get the job done. (This is wonderfully powerful, so much so you should be sure to only do it in an isolated VM.)
When you are done, in the exe.dev web UI you will find a share URL under your VM:
https://anycaster.exe.xyz?share=AVERYSECRETTOKEN
Send that to anyone and they can login by verifying their email (no subscription required). Your app is private by default but shared easily.
Example: anycaster
This is the “show, don’t tell” part of the post. Here is a real app I wrote, on my phone, to do serious work.
As part of rolling out exe.dev to multiple regions, we are exploring putting all of our VMs automatically behind a global anycast network. The sort of thing you might buy, e.g. AWS GLB, but we are doing it with more direct vendors because, well, we intend to be a cloud provider. That means doing the work.
So we rolled out a small set of global frontends and had a /24 anycast onto it by one of the vendors. It seemed to work. But I noticed surprisingly long ping times from home. So I added an endpoint to our frontends reporting location, much like you can do with Cloudflare:
curl -s https://1.1.1.1/cdn-cgi/trace | grep colo
What I found was my home network (in California) was misrouting to our Frankfurt frontend. Ouch.
So I wanted to report this to the netops team we are working with so they could fix it, but I also wanted to build out our own tooling for testing routes we care about. (These tools exist, but I wanted to log history and use them from my phone.) So I went to exe.dev/new, and typed in:
Hello. The anycaster server is designed to test exe.dev anycast.
Setup Tailscale with the token:
TS_TOKEN=...
Write a Go server that, every hour, uses
`tailscale exit-node list --filter=` to find a Mullvad exit node in
the right region, uses `tailscale set --exit-node=` to set the
machine to use it, and then inspects the state of the world with:
curl -s https://1.1.1.1/cdn-cgi/trace | grep colo
This is our base standard about "where we are".
Then run:
curl -s http://<our anycast IP>/debug/who
This is the test of our anycast, and tells you which of our servers
we are connected to. You can get the list of frontends with: …
I want you to test access from (and if these exact locations don't
exist, something geographically near): …
Then for each of these run:
sudo mtr -rwzbs 200 --tcp -P 80 <our anycast IP>
to give us a route to the target.
Store the results in an sqlite DB.
Each of these should connect to the geographically closest FE.
Show the latest results on the web page of anycaster.
This is a long prompt to type out on a phone, but I was walking to a meeting and I generally type far too much on my phone. The TS_TOKEN I keep in an Apple Note for apps like these. (I realize that’s not great! I am working on trying to get Tailscale setup to be easier on exe.dev. You could also for this case skip Tailscale and use the mullvad client directly. But I write apps with what I know.)
I put my phone away, had the meeting, and then afterwards pulled it out and found this app waiting for me:
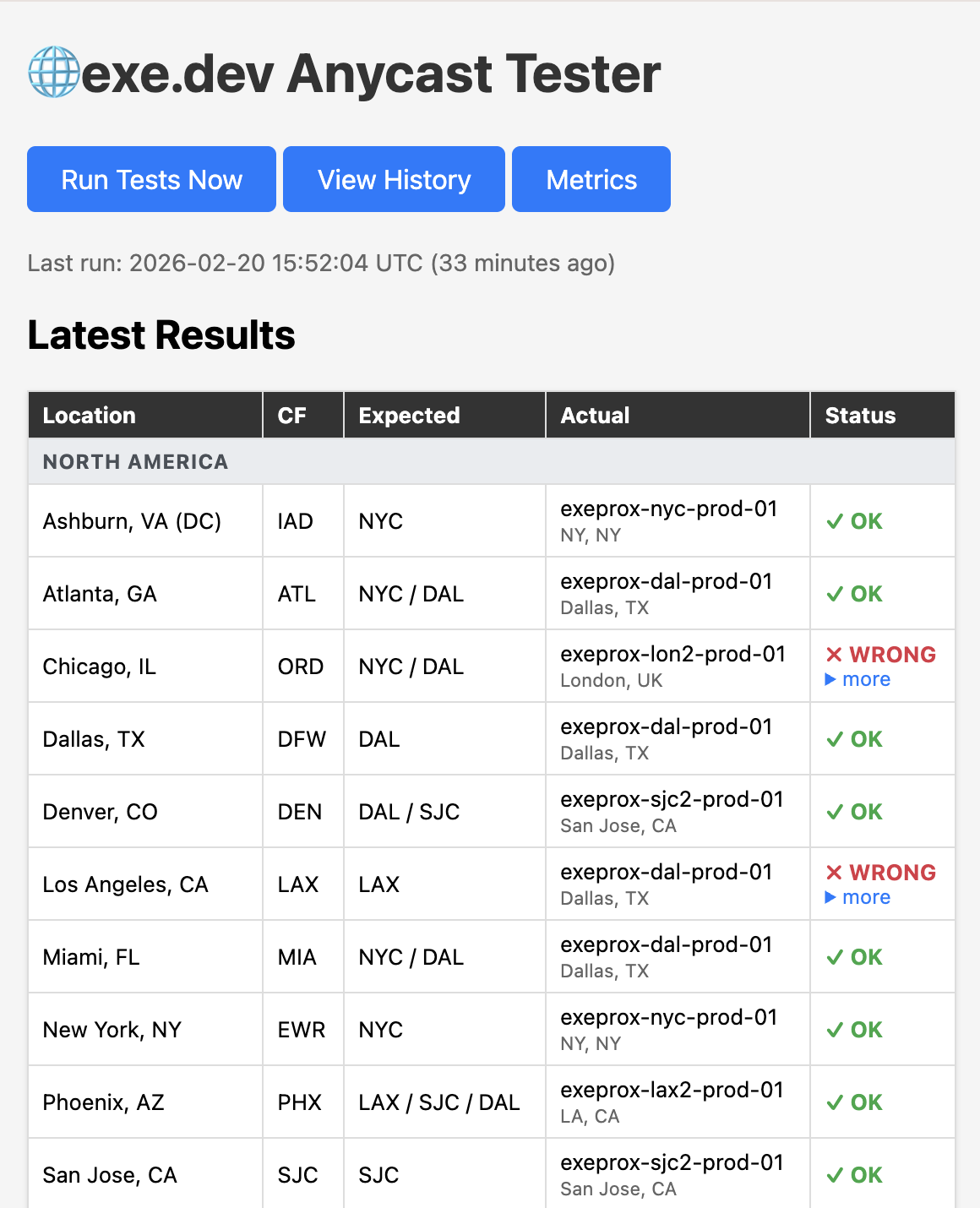
This is a recent screenshot. The original version had fewer frontends, and more ✗ results. Our anycast network needed a lot of tuning.
I sent the share link to the netops team and asked them to fix it. They did! Minus whatever strange thing is happening in Chicago, I still need to investigate if that’s weirdness from Mullvad or from our anycast routing.
Over the next couple of weeks I tweaked it. In my Shelley conversation history you’ll find prompts like:
Two things please:
- add an "edit in Shelley" button to anycaster to bring me here
- relax Miami so it can connect to DAL
And:
We now have enough things to test that it's slow. I believe all
the time is in running mtr. So let's do it in two phases:
1. go through them all and collect status.
2. when complete, go through the ones that fail and collect MTR.
Make it clear what's happening visually.
One big thing I changed was, every hour when this server ran the test, switching the exit node cut off my access to the web server. We have a plan to fix this generally for exe.dev users by improving some of our in-VM isolation, but until we did I wanted a quick fix. Out of curiosity, I typed in this prompt:
The current anycaster works well. However, when it is running the tests, the reconfiguration of Tailscale appears to break the exe.dev sshd server and thus the website (which proxies through it).
Is it possible to use Tailscale in an isolated network namespace?
We can then run our connection tests like the mtr tool in that namespace.
Please try implementing it.
This was me, honestly, being silly. There is no world in which I would waste hours digging through the poor documentation around the netns command for a little dashboard app like this, all over a minor inconvenience. I could lose a couple of days to something ridiculous like this in the pre-LLM world. But when you’re typing idly on a phone you can dream of software you would never realistically write.
When I came back Shelley left me with a summary and some ASCII art:
### Changes Made
1. **`tailscale-netns.service`** - New systemd service that:
- Creates a Linux network namespace called `tailscale`
- Sets up a veth pair (`veth-host` ↔ `veth-ts`) to connect namespace to host
- Configures IPs (10.200.200.1/24 on host, 10.200.200.2/24 in namespace)
- Enables IP forwarding and NAT so namespace can reach the internet
- Cleans up on stop
...
### How It Works
┌─────────────────────────────────────────────────────────┐
│ HOST (exe.dev VM) │
│ │
│ eth0 ─────────────────────────────────► Internet │
│ (exe.dev sshd uses this directly) │
│ │
│ veth-host (10.200.200.1) │
│ │ │
│ │ NAT │
│ ▼ │
│ ┌───────────────────────────────────────────┐ │
│ │ NAMESPACE "tailscale" │ │
│ │ │ │
│ │ veth-ts (10.200.200.2) │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ tailscale0 ────► Exit nodes ────► Tests │ │
│ │ │ │
│ └───────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
- **Host traffic** (including exe.dev sshd) uses eth0 directly
- **Anycaster tests** run `curl`/`mtr` inside the namespace
- **tailscale CLI** commands work from outside
(socket-based communication)
It worked.
It dug its way through all these painfully undocumented Linux subsystems and isolated my Tailscale daemon in a network namespace. Every hour when the namespace starts changing its location, I can still access the web server. In fact I wrote a few more prompts to add nice status updates about the background work to the UI.
The result of all of this is we are still investigating and trialing vendor products for our global network frontend, and studying how these products handle changing network routes. We hope to launch something soon.
A note on the future of engineering
What is surprising to me, in retrospect, is at no point in writing or using this app, or sharing it with half a dozen netops folks, did I ever look at the code. I spot checked the outputs, I looked at the bad mtr traces and made sure the conclusions fit with the data. We eventually cross-checked with RIPE. The output is correct. I am writing serious business tools that affect the company’s decisions, with prompts, from my phone.
Again, I don’t want to oversell anything. I have used Shelley to prototype changes to our web UI and add minor features. But almost all of our changes to exe.dev infrastructure are done on desktop. We read source changes to critical systems very carefully.
What we see here is a new kind of small private shareable app development appearing. You won’t be writing a web browser in it any time soon. But you might be building fun programs for friends or colleagues that you couldn’t fit in a spreadsheet.
Write some fun games with your kids on the couch. Or clone a round of Only Connect. Before you know it you will think of something you need at work and want to share with the team.